



Photo by Susan Q Yin on Unsplash
How I created NextRead, an author recommendation web app that finds authors who wrote/are mentioned in book endorsements


Disclaimer: This blog post is not related to my current job with NIWC Atlantic or the Department of Navy whatsoever.
The Idea
I just finished reading a book, what's next?
Typically I find new authors through their book endorsements found on the cover of the book I just read. However, I have not found a website that helps you find new authors by finding them through their endorsements of other authors. So I created NextRead.
Please check out NextRead here
The GitHub rep for NextRead is here
What does it do exactly?
There are plenty of website that have user-driven communities for book lists and reviews (GoodReads Lists, Amazon book reviews, book clubs, etc). However, I may not be the majority in saying this, but I appreciate reading new authors that other authors have read and endorsed on the book cover, or were mentioned in book endorsements.
Which book APIs to use?
Now that I had my idea and what I wanted it to do, I focused on which book APIs I would use, knowing this would drive other decisions down the road. Below is what I found researching book APIs:
Amazon Product Advertising 5.0 - While Amazon's book descriptions arguably have the most book endorsement information, as a federal employee I cannot link to Amazon products for money so that option was out.
GoodReads API - Technically this API is also an Amazon entity, but even if they were not, this API was retired on Dec 8, 2020, so also not an option.
Paid API Options - As this was a personal project to highlight my experience with AWS/Serverless architecture and wanting to stay above-board with my current employer, I decided to stay away from these options.
Google Books API - Their API is free to use , shows in-print and out-of-print books, shows digital/physical/audiobooks; this is exactly what I needed for this project.
WorldCat - I knew I wanted to steer clear of any financial perks linking my website to Amazon or similar sites, so I decided why not link to a website that can help you find books at your library for free, which is exactly what WorldCat does.
The Architecture
Below is a high-level view of how NextRead Processing works:
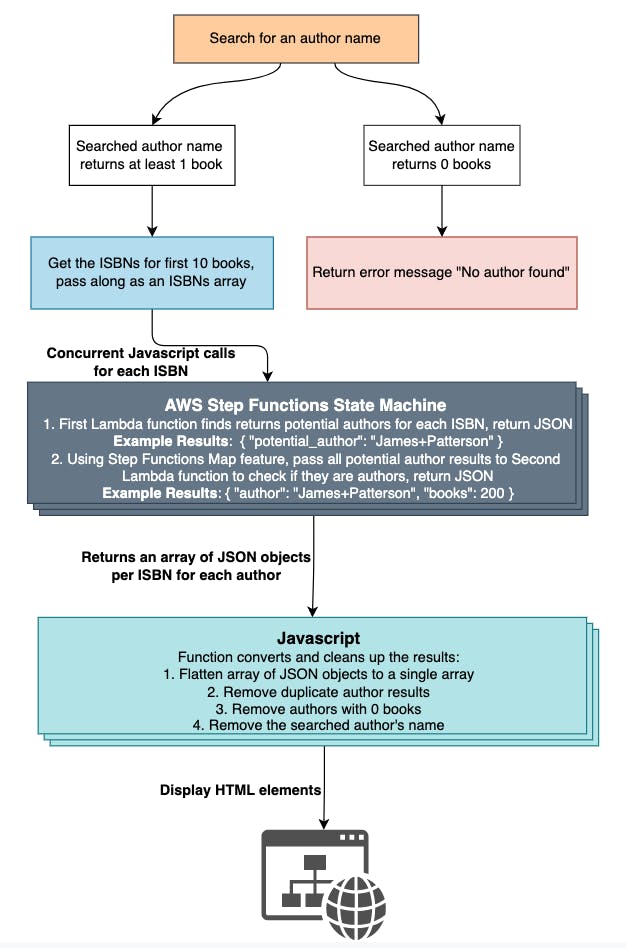
The main technologies used in making this project include:
- API Gateway - I use a simple REST API as the front-end to pass in the ISBN for processing.
- Lambda functions - I wrote one Lambda function which passes in the ISBN to get the potential authors array, and a second Lambda function which verifies which potential authors are actual authors.
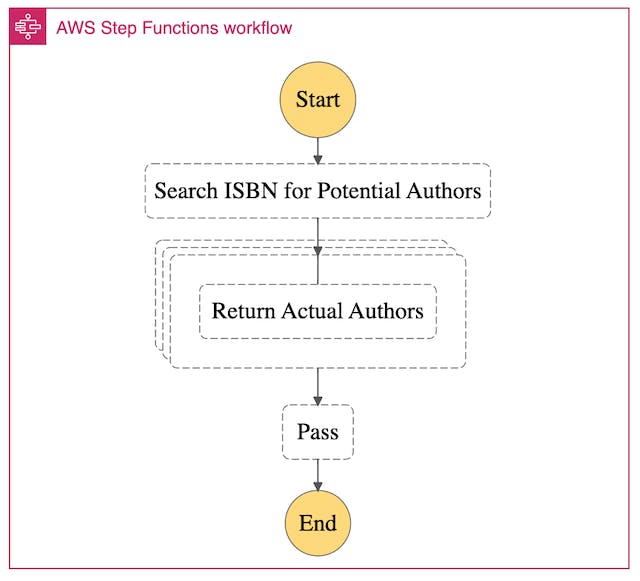
- AWS Step Functions - Below shows the flow of my State Machine, which passes in the ISBN, and returns all consecutive words that are in the title case. Then, I use Step Function mapping to call my second Lambda function for each JSON object result from my first Lambda function. This is extremely fast and powerful running them concurrently for each ISBN.
- Javascript Functions - This was more intensive than I thought it would be. I had to process making the Initial Google Books API call for an author, figure out how to make nested concurrent API calls, and then clean up the results into an array and display using HTML elements. I also learned a great deal about Javascript Promises and ultimately decided to run my API calls quasi-concurrently using Promise.allSettled() instead of Promise.all() since I'd rather give the user partial results over zero results should the API calls fail for any reason.
API Constraints
While I appreciate the Google Books API being both free and robust, I did have some challenges. One thing I noticed was the relevancy of books returned after 8-10 books started to decline. This is why I set the hard limit of books per author I looked up to be 10 books.
Python Highlights
Get Potential Authors Lambda function
Below is part of my Python code which shows how I traversed over the book description and returns JSON objects with potential author names.
for index, word in enumerate(description):
# Start only if the description has at least 2 words, and verify each word is not a common word
if (index >= 1 and not_common_word(description[index-1]) and not_common_word(description[index])):
# Check for 2 adjacent words to be title case, add to the potential_author array is true
# A plus sign is added for the next API call
if (description[index-1].istitle() and description[index].istitle()):
potential_authors.append({'potential_author': description[index-1]+"+"+description[index]})
# Keep only distinct potential authors values
potential_authors = [i for n, i in enumerate(potential_authors) if i not in potential_authors[n + 1:]]
return {"potential_authors": potential_authors}
Get Valid Authors Lambda function
Below is part of my Python code which validates if a potential has any books attributed to them with ISBN-10 value.
book_api = "https://www.googleapis.com/books/v1/volumes?q=author:" + \
'"'+potential_author+'"'
resp = urlopen(book_api)
book_data = json.load(resp)
# Verifies if the potential author has any books attributed to them
if (book_data['totalItems'] > 0):
one_good_book = False
# Iterate over all books returned
for index, book in enumerate(book_data['items']):
if ('industryIdentifiers' in book['volumeInfo']):
# At least one book in author's books must have an IBSN_10
for id in book['volumeInfo']['industryIdentifiers']:
if (id['type'] == 'ISBN_10'):
one_good_book = True
# Verify returned book has authors listed and at least one book
# with an ISBN_10 value, other return with 0 books
if ("authors" not in book['volumeInfo'] or not one_good_book):
return {"author": potential_author, "books": 0}
# Assign authors JSON value to authors variable
authors = book['volumeInfo']['authors']
# Iterate over all authors and verify the potential author
# passed into the function is an exact match to an author's name returned,
# not just a partial substring match. The space is replaced with a plus sign for API call
for author_index, author in enumerate(authors):
if (potential_author.replace('+', ' ').lower() == author.lower()):
return {"author": author, "books": book_data['totalItems']}
# If the potential author is not an author, return None
else:
return {"author": potential_author, "books": 0}
Javascript Highlights
The below code shows how I took an array of arrays with null values, duplicate authors, and empty arrays and created one clean Javascript map object.
// Flatten multiple author array results into one flat authors array
flattened_authors = authors.flat();
// Remove "falsy" authors from the flattened_authors array
filtered_authors = flattened_authors.filter(Boolean);
// Remove authors with 0 attributed books
for (var i = filtered_authors.length - 1; i >= 0; --i) {
if (filtered_authors[i].books === 0) {
filtered_authors.splice(i, 1);
}
}
// Create a map of authors which does not allow duplicates of authors,
// and this maps the JSON data returned in the format "author:books"
var map_of_authors = {};
map_of_authors = Object.assign(
{},
...filtered_authors.map((x) => ({ [x.author]: x.books }))
);
Future Features
False positives for author names - Some author names that I don't want to show in my results include proper names like "South Dakota" and "TIME Magazine", and some small word combinations like "IT And." Technically it found author names where these values were a subset of the full author name, but my intention was to return only a person's name, not companies/locations/etc.
Fictional character names being the same as real authors - For example, Jack Reacher is a fictional character from the popular author Lee Child. However, that is also the name of an author who wrote the book "A Heartbeat Away." When I scan through a book description, I have no way of knowing which of these 2 people are being mentioned.
One possible solution to both these problems is make the resolution community-driven. I could have a button meant for users to mark an author as not relevant. This button could trigger an API call that write to a DynamoDB table of words/names to exclude in the results. This sounds like a decent amount of work, and for my needs currently, I don't mind needing to ignore some of the bad results.
Thanks, please check out GitHub here to learn more.
I hope you enjoy using NextRead!