



Photo by rupixen.com on Unsplash
Flattening the Curve: My thought process building async processing in the Cloud Resume extra credit challenge


Disclaimer: This blog post is not related to my current job with NIWC Atlantic or the Department of Navy whatsoever.
Introduction
I completed the Cloud Resume Challenge, woohoo! Now what do I do?
At the end of the book, there are extra credits challenges that focus on different real-world scenarios. I was drawn toward "Flattening the Curve: Architecting asynchronous processing on AWS" by Jennine Townsend.
NOTE: I don't intend to ruin this extra challenge for any other people trying to complete it, but the purpose of this blog post is to highlight my lessons learned.
Flattening the Curve
This challenge's goal was to mimic an example website that has the potential of overloading resources by running too many concurrent jobs, causing problems like latency, downtime, errors where the result would be angry users. To help not anger users, the goal is "flatten the curve" which means to limit the high usage peaks on our resources spreading out the jobs over time.
To mimic a website in this scenario, I used the below items:
- Process Lambda function - This function mimics what is the website's main purpose (for example, uploading images for an image conversion website). In my case, I am writing basic event information to the logs.
- SQS Queue - This queue will hold the messages sent from our Trigger function.
- Trigger Lambda function - This function sends a SQS message to the queue.
- Lambda SQS trigger - I hooked up the SQS queue as a Lambda trigger to the Process function.
- Local Python code to call Trigger Lambda function - This Python file has a function that can call the Lambda function numerous times to assist me in verifying I am flattening the curve.
Testing it out
My local Python code called my Trigger Lambda function 100 times in a loop and would pass into the function a random integer between 10 and 100 to pseudo-randomly delay my messages to hit the SQS queue.
I set a 2 second sleep timer inside my Process function to increase the function duration and hopefully see more concurrent connections since simply writing event information to CloudWatch is incredibly fast.
To force errors so that I could see them in action, I set my sleep time higher than 3 seconds, which the Lambda timeout threshold. I also changed my upper/lower limit for my delay value.
Lessons learned reviewing CloudWatch
I've included screenshots below to help show visually the progress in flattening the curve simply by adding in random integer values to the DelaySeconds argument in sending SQS messages. After reviewing these screenshots, I'll give my last thoughts on other methods to flatten the curve.
My first peak on the Invocations image below was without the SQS message DelaySeconds set with a value of 129 invocations. The last and highest peak on the Invocations image did have DelaySeconds set with a random integer with a value of 231 invocations.
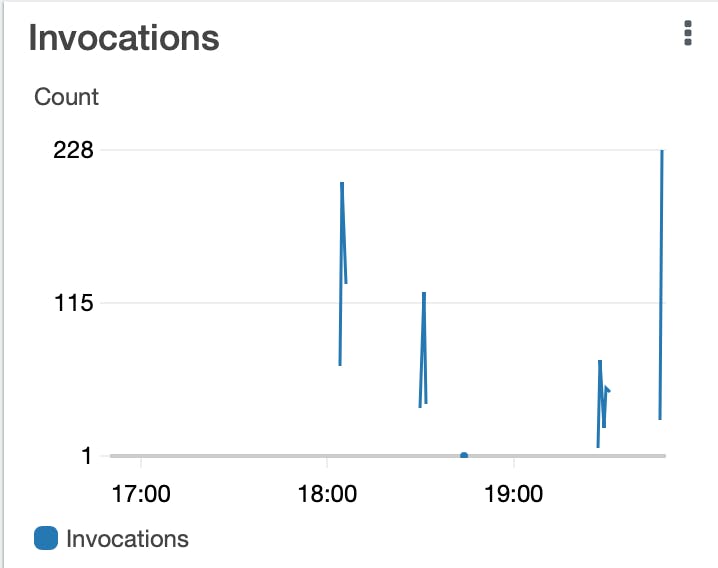
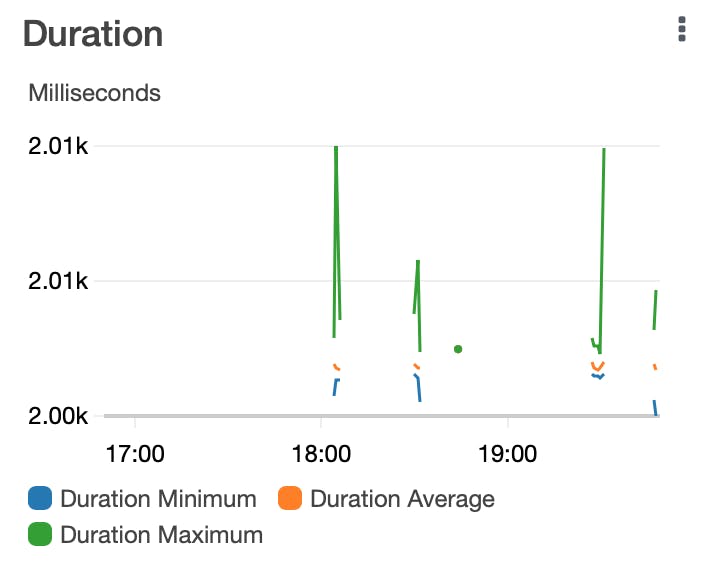
Because this is a test and my Lambda function only sent minimal information to CloudWatch, the Duration image is not super exciting to review since the duration did not change.
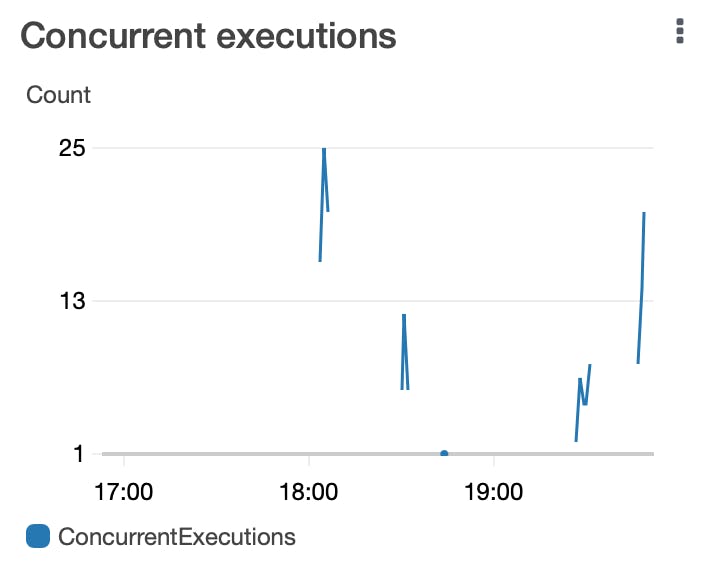
Matching the peaks listed above from the Invocations image, you can see an improvement in number of concurrent executions once I set the DelaySeconds value in sending the SQS message. Sending almost twice the number of invocations still wasn't enough to match the number of concurrent executions, that's great news!
CloudWatch Alerts
To help automate monitoring this design, I used CloudWatch metrics to alert me when certain thresholds were met. Specifically I matched capturing metrics with what question did I want to answer:
- Concurrent Executions - How many jobs are running at the same potentially affecting performance?
- Error Count - How many potentially anger customers might I have if my system is failing?
- Invocations - How frequently is my website getting hits potentially affecting performance?
If this was a real-world scenario, I would include the following metrics capturing:
- Memory Usage - Do my Lambda functions have not enough/use too much memory, potentially affecting performance and cost?
- Billed Duration - How much are my Lambda functions costing my organization?
Other methods to flatten the curve
If this truly was an image converting website, instead of using a random integer in DelaySeconds, I could use one of the following methods to help my resources not be overburdened:
- Use different SQS queues for paying vs non-paying customers
- If I was to keep one SQS queue, I could use the metadata of the file (i.e. file size) being uploaded to help set my DelaySeconds value
- Making sure my front-end visible to the customer shows them progress to hopefully minimize frustration with wait time, and so they don't attempt to re-upload the same files numerous times taxing my resources
Check out my code on Github repo here